Aufgabenblatt 1 - LDAP
Bitte lesen Sie die Einleitung.
Dann loggen Sie sich bitte auf den Rechner quak ein.
1. Aufgabe
- Legen Sie ein Datenverzeichnis für den LDAP-Server an, falls ihr home-Verz. zu klein ist, geht
das auch im /tmp - Verzeichnis.
- Laden Sie sich eine slapd.conf herunter und passen sie die Pfade an.
- Als nächstes benötigen Sie die LDIF - Daten, diese werden mit dem
Befehl: /usr/sbin/ldif2ldbm -f slapd.conf -i data.ldif eingespielt. Die Zeitdauer hierfür messen Sie bitte entweder mit einem kleinen Shell- oder Perlskript.
Für alle die noch nie ein Shell oder Perlskript geschrieben haben ist hier ein Rahmenprogramm, das die Zeit misst. Einfach in die Anführungszeichen hinter "system" den auszuführenden Befehl eintragen, das Programm dann mit perl A1.pl starten. Die Ausgabe ist die Ausführungszeit in sek.
- Zum Schluss lesen Sie die man - Pages zu slapd und starten Ihn auf einem Port zw. 1090 - 1099.( sollten sie mit ihren Kollegen absprechen!)
Achtung: Wenn Sie sich von einem Windows Rechner per ssh auf die Uni Rechner einloggen, achten Sie darauf, dass alle bearbeiteten Dateien im Unix Format auf Ihrem Account liegen.
Abgabe:
- Benötigte Zeit für LDIF
- Ausgabe aller Hotels in Esslingen :)
2. Aufgabe
Wie ihnen bestimmt aufgefallen ist, fehlt eine Beschreibung der Hotels. Diese werden wir nun mit ldapmodify hinzugefügen.
- Lesen Sie die Dokumentation
zu der ldapmodify durch und spoolen Sie die Daten aus description.ldif ein
Abgabe:
- Zeitdauer
3. Aufgabe
- Holen Sie sich das Rahmenprogramm und lesen Sie sich in RFC 1823 die Doku zu
ldap_search_s() durch.
- Vervollständigen Sie das Programm, so dass es alle Hotels ausgibt, welche ein Bad besitzen und eine 7'er PLZ haben.
Abgabe:
- Sourcecode
- gemessene Zeit
4. Aufgabe
- Killen sie Ihren slapd :)
Bemerkung:
Der Rechner quak ist relativ langsam und wird ausserdem noch zusätzlich durch diese Aufgabe belastet, deshalb
sollten Sie u.U. eine Messung wiederholen, falls die Zeiten zu unplausibel sind.
Abgabe bitte per Mail an Stefan Munz
Aufgabenblatt 2 - CORBA mit Java
Inhalt dieser Seite:
Was ist CORBA?
Das Vorgehen bei der
Entwicklung mit CORBA
Die vom IDL-Compiler
erzeugten Dateien
Unsere Beispiel-Anwendung
Ihre Aufgabe
Was ist CORBA?
Die Common Object Request Broker Architecture (CORBA) ist ein Standard
zum Verteilen von Objekten über ein Netzwerk.
Er wurde von der Object Management Group (OMG), einem nicht
profitorientierten Standardisierungsgremium mit mehr als 700 Mitgliedern
(Softwareentwickler, Netzwerkbetreiber, Hardwareproduzenten und kommerzielle
Anwender von Computersystemen, unter anderem SUN, IBM, ...) 1991 in der
ersten Version definiert.
Ziel war, eine Middleware zu schaffen, welche eine orts-, plattform-
und implementierungsunabhängige Kommunikation zwischen Applikationen
erlaubt.
Ein Vermittlungsdienst (Object Request Broker = ORB) gewährleistet
dabei das Zusammenarbeiten von Objekten über Rechnergrenzen hinweg.
Wirklich interessant geworden ist CORBA seit der Verabschiedung der
Version 2.0 im Dezember 1994. Diese Version brachte das Kommunikationsprotokoll
IIOP, welches die Kommunikation zwischen Object Request Brokern (ORB) verschiedener
Hersteller und vor allem auch über das Internet ermöglicht.
CORBA zeichnet sich durch folgende Eigenschaften aus:
-
Objektorientierung.
Die grundlegenden Einheiten der Architektur sind Objekte.
-
Verteilungstransparenz.
CORBA-Programme greifen auf entfernte Objekte mit denselben Mechanismen
zu, wie auf lokale Objekte. Der genaue Aufenthaltsort eines Objekts bleibt
für seine Klienten in der Regel unbekannt.
-
Effizienz.
Die Architektur für den ORB ist von der OMG bewußt so gehalten,
daß effiziente Implementationen möglich sind, die z.B. im Falle
rein lokaler Kommunikation dem traditionellen Funktionsaufruf nur unwesentlich
nachstehen.
-
Hardware-, Betriebssystem- und Sprachunabhängigkeit.
Die Komponenten eines CORBA-Programms können auf verschiedenen
Betriebssystemen, Hardwarearchitekturen und mit verschiedenen Programmiersprachen
realisiert werden.
-
Offenheit.
Über den ORB können Programme verschiedener Hersteller zusammenarbeiten.
Der Anwender erhält dadurch die Freiheit, jede Komponente bei dem
Anbieter kaufen zu können, der seinen individuellen Bedürfnissen
am besten gerecht wird. Softwareentwickler erhalten die Chance, am Softwaremarkt
von morgen teilzuhaben und Angebote großer Firmen mit spezialisierten
Produkten zu ergänzen.
CORBA stellt also zum einen eine beachtliche Menge technologischen Know-hows
und zum anderen einen selten erreichten Konsens innerhalb der Computerindustrie
dar.
Begriffe und Abkürzungen:
-
ORB
Der Object Request Broker (ORB) ist der Kommunikationsbus zwischen
CORBA-Objekten.
Er bietet einen Mechanismus an, um Anfragen des Clients an die entsprechenden
Objekt-Implementierungen weiterzuleiten, und zwar unabhänigig davon,
an welchem Ort sich diese im Netzwerk befinden und unter welchem Betriebssystem
sie dort laufen.
Der Client braucht dabei nicht zu wissen, ob sich das Objekt auf dem
gleichen Computer befindet oder auf einem Remotecomputer irgendwo im Netz
sitzt. Er muß nur den Namen des Objekts oder die Objektreferenz kennen
und wissen, wie man die Schnittstelle des Objekts benutzt.
Der ORB kümmert sich um die Details: Das Lokalisieren des Objekts,
die Weiterleitung des Aufrufs und das Zurückliefern des Resultats.
Hinter einem einfachen Methodenaufruf des Clients verbirgt sich also
eine komplexe Netzwerkkommunikation, die vom ORB gehandhabt wird:
Eine Anfrage des Clients, bestehend aus dem Methodenaufruf und den
Parametern, wird in einem binären Strom umgesetzt (marshaling) und
über das Netzwerk an den Server geschickt. Die Informationen werden
auf der Server-Seite wieder decodiert (unmarshaling) und die gewünschte
Operation ausgeführt. Rückgabewerte werden auf die gleiche Weise
wieder über den ORB an den Client gesendet.
Zusammengefaßt hat der ORB die Aufgabe, die dem Aufruf des Clients
entsprechende Objektimplementierung zu finden, sie -falls erforderlich-
zu aktivieren, die Anfrage an das Objekt zu leiten und entsprechende Rückgabewerte
wieder an den Client zurückzugeben.
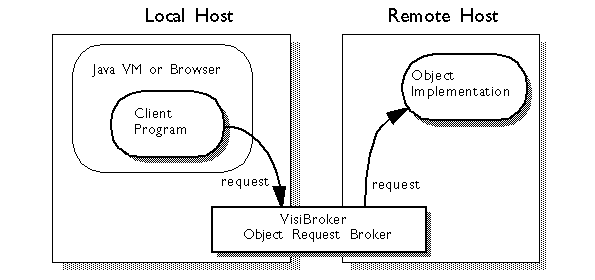
Abbildung entnommen aus: "INPRISE Corporation: VisiBroker
for Java 3.0, Programmer's Guide".
-
Stubs und Skeletons
Stubs stellen für den Client die Schnittstellen zu den Server-Diensten
(Objektmethoden) bereit.
Aus der Sicht des Clients verhält sich der Stub wie ein Proxy-Objekt
für ein entferntes Server-Objekt.
Die Server-Objekte werden mit Hilfe von IDL definiert, ihre zugehörigen
Client-Stubs vom einem IDL-Compiler generiert. Ein Stub beinhaltet Code
für die Umsetzung der Methodenaufrufe mit ihren Parametern in einfache
Nachrichtenströme, die an den Server gesendet werden. Die zugrundeliegenden
Protokolle oder Dinge wie Datenanordnungen bleiben für den Client
vollkommen transparent, der die Dienste als einfache Methodenaufrufe auffaßt.
Skeletons stellen das Gegenstück zu den Client-Stubs dar. Sie
stellen die statischen Schnittstellen für jeden vom Server unterstützten
Dienst bereit. Sie beinhalten Code, um eingehende Nachrichten in normale
Methodenaufrufe umzusetzen und diese auszuführen. Rückgabewerte
werden wieder über die Skeletons in einem binärem Strom umgewandelt
und an den Client zurückgeschickt.
Wie die Stubs werden die Skeletons vom IDL-Compiler aus IDL-Interfaces
generiert.
-
IDL
CORBA wurde so spezifiziert, daß es sprach- und betriebssystemunabhängig
ist.
Dazu ist eine einheitliche Schnittstellenbeschreibung der zu verteilenden
CORBA-Objekte erforderlich. Diese Beschreibungssprache ist im CORBA-Standard
als IDL (Interface Definition Language) definiert und an die Syntax von
C/C++ angelehnt.
Die Operationen und Attribute, die von einem Server der "Außenwelt"
zur Verfügung gestellt werden sollen, werden zunächst in einem
Interface mittels IDL beschrieben. Aus einem vollständig beschriebenen
IDL-Interface werden dann mit einem IDL-Compiler Stub-Klassen für
die Clients und Skeleton-Klassen für den Server in der jeweiligen
Programmiersprache erzeugt.
Ein IDL-Interface beschreibt dabei lediglich die Schnittstellen der
zu veröffentlichenden Dienste und Komponenten des Servers. Es enthält
keine Implementierungen. Dadurch wird ermöglicht, daß beispielsweise
in Java erstellte Clients auf in C++ realisierte Server-Objekte zugreifen.
-
Interface Repository
Das Interface Repository ist eine vom ORB unterhaltene Online-Datenbank,
die zu jeder Objekt-Klasse die Beschreibung ihrer Interfaces enthält.
-
Implementation Repository
Das Implementation Repository enthält Informationen zu allen Objekt-Instanzen.
Jedes Objekt wird darin durch eine eindeutige Objektreferenz identifiziert.
Da CORBA-Objekte keine laufenden Prozesse sein müssen, ermöglicht
das Implementation Repository jederzeit die Aktivierung eines angesprochenen
Objekts.
-
BOA
Der BOA (Basic Objekt Adapter) ist für die Verbindung der Server-Objekte
mit dem ORB zuständig.
Er hat die Aufgabe, Objekte im Implementation Repository zu registrieren
und Objekte zu aktivieren und deaktivieren.
-
Objektreferenzen und IOR
Eine Objektreferenz ist eine Zeichenkette, die ein Objekt innerhalb
eines verteilten CORBA-Systems eindeutig kennzeichnet.
ORBs unterschiedlicher Hersteller übermitteln Objektreferenzen
nach dem IOR-Standard (IOR = Interoperable Object Reference).
-
IIOP
Das IIOP (Internet Inter ORB Protocol) ist ein Netzwerkprotokoll für
die Kommunikation zwischen ORBs.
Das Vorgehen bei der Entwicklung mit CORBA
Prinzipiell erfolgt die Entwicklung einer CORBA-Anwendung stets in den
gleichen drei Schritten:
-
IDL-Datei schreiben, d.h. die Schnittstelle der (Server-)Objekte spezifizieren,
und mit dem IDL-Compiler kompilieren
-
Server implementieren
-
Client implementieren
Das von uns im Praktikum verwendete Produkt ist der VisiBroker for Java
3.0 von Visigenic.
Dieses Paket enthält unter anderem die CORBA-Klassen, den IDL-Compiler,
sowie weitere für die Entwicklung und den Betrieb von CORBA-Anwendungen
nötige Werkzeuge und Programme.
Die Online-Produktdokumentation (zwei Teile: "Programmers´s Guide"
und "Reference") dazu finden Sie unter der URL http://www.borland.com/techpubs/visibroker/visibroker30/.
Sie bekommen unter dieser Adresse die Dokumentation wahlweise entweder
als HTML-Dokument oder im PDF-Format.
Die folgende Kurz-Einleitung kann nicht die Beschäftigung mit
dieser Dokumention (z.B.: "Programmers´s Guide", Kap. 1: "VisiBroker
Basics", Kap. 2: "Getting started") ersetzen und soll Ihnen lediglich einen
einfachen Einstieg verschaffen.
Bei der Programmierung gehen Sie nun also wie folgt vor:
-
IDL-Datei schreiben, d.h. die Schnittstelle der (Server-)Objekte spezifizieren,
und mit dem IDL-Compiler kompilieren
Nehmen wir an, Sie möchten eine Klasse "MeineKlasse" mit vier Methoden
im Netz zur Verfügung stellen.
Ihr IDL-Interface könnte dann in etwa so aussehen:
module Test {
interface MeineKlasse {
void tunix();
long tuwas(in float zahl);
short tuwas2(inout long zahl);
float tuwas3(out short zahl);
};
};
Die Art eines jeden Parameters (in, inout, out) gibt
dabei an, ob mit dem jeweiligen Parameter nur ein Wert an die Methode übergeben
werden soll (in), oder ob über diesen Parameter auch ein Wert
zurückgegeben wird (inout, out).
Sie schreiben also die IDL-Datei und speichern sie z.B. unter dem Namen
Test.idl
ab. Anschließend compilieren Sie sie mit dem Kommando
idl2java
Test.idl -no_tie (die Option -no_tie bezweckt lediglich, daß
der IDL-Compiler keine Dateien generiert, die wir in unserem Fall nicht
benötigen).
Nicht erschrecken: Der IDL-Compiler legt Ihnen nun ein Verzeichnis
mit dem Namen Test an, in dem sich eine Unzahl von Dateien befindet,
die sich von den ORB-Klassen ableiten und über weitere Vererbung die
entsprechenden Methoden soweit anpassen, bis sie mit den IDL-Interfaces
übereinstimmen. Für Java werden dabei sehr viele Dateien erzeugt,
da Java keine Mehrfachvererbung unterstützt und außerdem nur
eine Klasse pro Datei erlaubt ist.
Je nach Compileroptionen und Art der Klasse werden so pro in der IDL-Datei
definierter Klasse ca. fünf Dateien generiert, die alle zusammen das
Package Test bilden.
Wir werden weiter unten noch auf diese Dateien zurückkommen.
-
Server (in Java) implementieren
Hier müssen Sie zunächst die Klasse mit den Methoden, die
Sie bereitstellen möchten, implementieren.
Außerdem müssen Sie das Objekt mittels des BOAs beim ORB
anmelden und für einen Mechanismus sorgen, der das Objekt aktiviert.
Im Falle von Visigenic wird die Aktivierung entweder bei Bedarf von
einem extra gestarteten Prozess, dem "Object Activation Daemon (OAD)",
automatisch erledigt, oder aber sie aktivieren das Objekt mit Hilfe des
BOAs selbst und warten dann auf die Anfragen der Clients. Dies können
Sie entweder in der main-Methode des Objekts oder aber (wie gleich
in unserem Beispiel) in einem separaten Serverprogramm tun.
Bei der Implementierung Ihrer Klasse erweitern sie per Vererbung die
vom IDL-Compiler generierte Skeleton-Klasse (in unserem Beispiel _MeineKlasseImplBase.java).
Nehmen wir an, sie nennen Ihre Implementation MeineKlasseImpl.java.
Nun schreiben Sie das Serverprogramm MeinServer.java. Wichtige
Kommandos hierbei sind:
Test.MeineKlasse klasse = new MeineKlasseImpl("Klassen_Name");
Diese Zeile erzeugt ein neues MeineKlasse-Objekt klasse.
Wichtig: Durch die Benutzung des Konstruktors mit String-Argument erzeugen
Sie ein sog. persistentes Objekt, welches von den Clients später anhand
seines Namens (hier: "Klassen_Name") gefunden werden kann.
Alternativ können sie auch ein namenloses transientes Objekt mit
dem argumentlosen Konstruktor erzeugen:
Test.MeineKlasse klasse = new MeineKlasseImpl();
boa.obj_is_ready(klasse); (Methode eines org.omg.CORBA.BOA-Objekts
boa)
Hiermit wird das Objekt klasse ins Implementation Repository
aufgenommen und vom BOA aktiviert.
boa.impl_is_ready();
Alle Objekte sind bereitgestellt, das Serverprogramm hat seine Aufgabe
erledigt. Mit diesem Kommando wird das Serverprogramm -und mit Ihm das
zur Verfügung gestellte Objekt- weiter am Leben erhalten. Dieses Kommando
ist das letzte im Serverprogramm, dieses befindet sich nun in einer Warteschleife,
nachfolgende Befehle werden nicht mehr ausgeführt.
Genauer erklärt finden Sie dies im "Programmers´s Guide",
Kap. 5: "Activating Objects".
-
Client (in Java) implementieren
Die Methoden, mit denen der Client das von ihm gewünschte Objekt
erhält, befinden sich in der vom IDL-Compiler generierten Klasse MeineKlasseHelper.java,
und zwar im wesentlichen die Methoden narrow und bind.
Von beiden gibt es mehrere Formen, die jeweils andere Argumente erwarten.
Der grundlegende Unterschied zwischen narrow und bind
ist, daß narrow die Objektreferenz benötigt, um das Objekt
zu finden, bind hingegen findet es aufgrund seines Namens oder liefert
einfach das erstbeste passende Objekt des gesuchten Typs zurück.
In unserem Fall wäre also die richtige Wahl:
Test.MeineKlasse klasse = Test.MeineKlasseHelper.bind(orb,"Klassen_Name");
Genauer erklärt finden Sie dies im "Programmers´s Guide",
Kap. 4: "Naming and Binding".
Sie haben nun also folgende Dateien vorliegen, die Sie mit dem Compile-Kommando
javac
*.java compilieren können:
MeinServer.java, MeineKlasseImpl.java und MeinClient.java,
sowie das generierte Verzeichnis Test.
Auf dem Serverrechner benötigen Sie MeinServer.java, MeineKlasseImpl.java
und das Verzeichnis Test, auf den Clientrechnern MeinClient.java
und das Verzeichnis Test.
Die VisiBroker-Dokumentation enthält hierzu ein sehr übersichtliches
Beispiel, das die Vorgehensweise verdeutlicht.
Die vom IDL-Compiler erzeugten Dateien:
-
MeineKlasse.java
Enthält das Interface Ihrer Klasse.
-
MeineKlasseHelper.java
Diese abstrakte Klasse enthält nützliche Methoden, um das
damit verbundene Objekt zu handhaben.
Für Objekte wie structures, enumerations, und unions
hält die Helperklasse Methoden zum Schreiben und Lesen bereit. Außerdem
bietet sie Methoden wie narrow und bind (s.o.).
-
MeineKlasseHolder.java
Die Übergabe von out- und inout-Parametern erfolgt
über die Holderklasse.
-
_st_MeineKlasse.java
Die Stub-Klasse.
-
_MeineKlasseImplBase.java
Die Skeleton-Klasse.
-
_example_MeineKlasse.java
Beispiel, wie Ihre Objekt-Implementierung aussehen könnte.
Genauer erklärt finden Sie dies in "Reference", Kap. 4: "Generated
Classes".
Unsere Beispiel-Anwendung
Das Programm, mit dem Sie sich in den nächsten drei Aufgaben beschäftigen
werden, ist ein Vier-Gewinnt-Spiel, mit dem Sie über Rechnergrenzen
hinweg gegeneinander oder gegen einen Computergegner spielen können.
Prinzipieller Aufbau des "VierGewint"-Systems:
-
Partie-Manager und Spielpartien
Der Partiemanager hat die Aufgabe, die laufenden Spielpartien zu verwalten.
Er startet bei Bedarf neue Spielpartien und weist diese den Clients zu,
die spielen wollen.
Jede Spielpartie enthält die Spiellogik und ein Spielfeld, so
daß immer zwei Clients in einer Spielpartie gegeneinander spielen.
-
Computerspieler
Der Computerspieler liefert auf Anfrage des Clients den besten Zug
für eine bestimmte Spielsituation zurück.
-
Client
Der Client beantragt entweder beim Partie-Manager eine neue Spielpartie
und wartet auf einen Gegner, oder er steigt als Gegner in einer vorhandenen
Partie ein, die er sich vom Partie-Manager holt.
Während des Spiels übermittelt er seine Spielzüge an
die Spielpartie und stellt das Spielfeld dar. Die zu übermittelnden
Spielzüge nimmt er entweder über die Tastatur vom Benutzer entgegen,
oder aber er fragt den Computerspieler nach dem im Moment besten Zug.
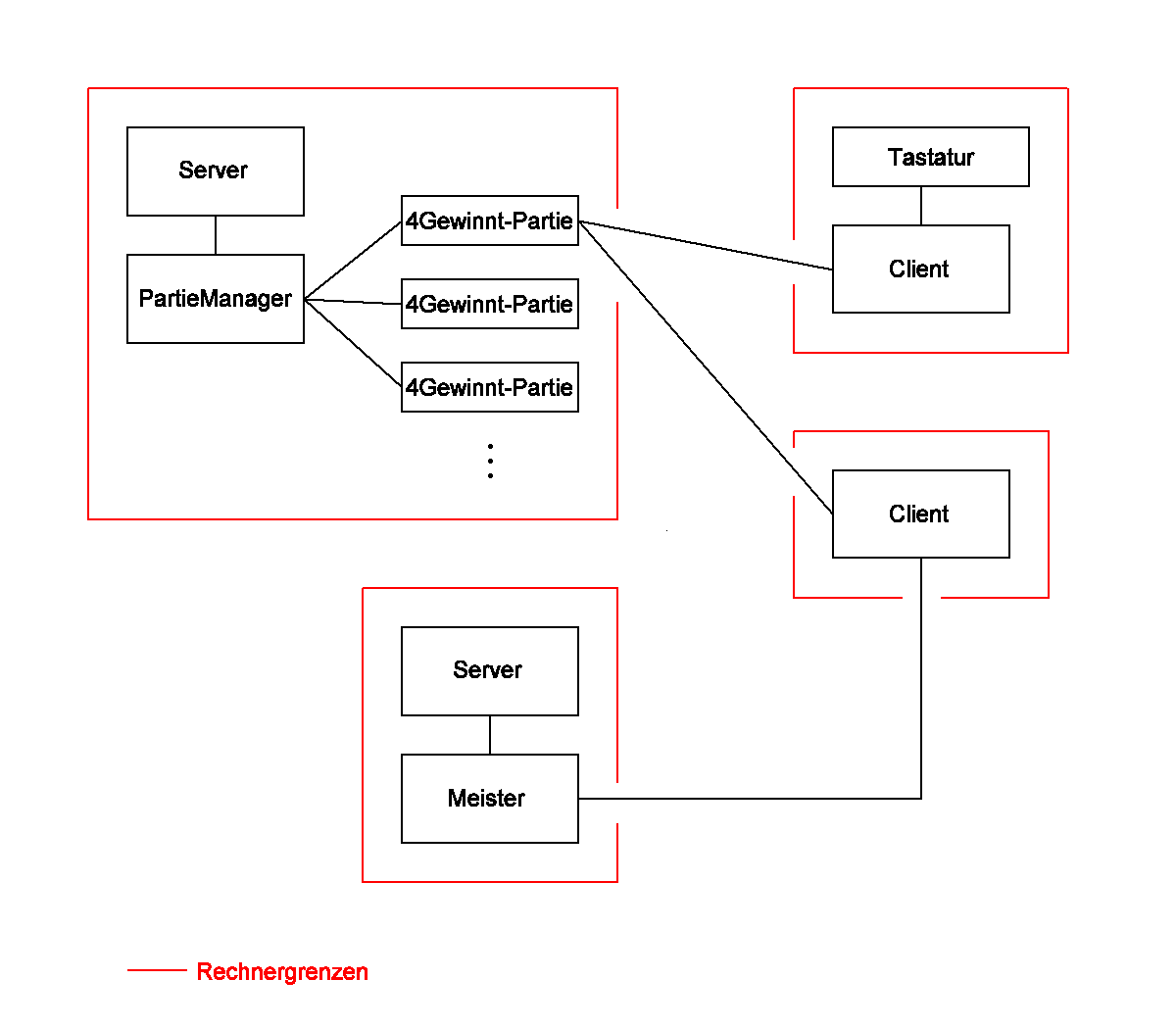
Für unsere Aufgabe vereinfachen wir diesen prinzipiellen Aufbau
folgendermaßen:
Der Partie-Manager und ein Computerspieler laufen auf einem Rechner,
es gibt also nur einen Server.
Die Verzeichnisstruktur unserer Anwendung
Alle Dateien, die Sie zur Praktikumsaufgabe benötigen, erhalten Sie
weiter unten als Zip-Datei.
Wenn Sie diese entpacken, werden folgende Verzeichnisse mit den darin
enthaltenen Dateien angelegt:
Aufgabe1
| VierGewinnt.idl
| vbroker.csh
|
+---ClientAufg1
| Client.java
|
+---ServerAufg1
PartieManagerImpl.java
Partie4GewinntImpl.java
Meister.java
Server.java
Die einzelnen Dateien:
-
VierGewinnt.idl
Das IDL-Interface, in dem einige Konstanten, der Spielfeld-Variablentyp
und die Interfaces unserer Objekte definiert werden.
-
vbroker.csh
Mit dieser Datei werden die benötigten Umgebungsvariablen gesetzt.
-
PartieManagerImpl.java
Das Partie-Manager-Objekt. Wird auf dem Serverrechner zur Verfügung
gestellt und verwaltet die Spielpartien.
Die öffentlichen Methoden:
public Partie4gewinnt spielen(String name)
Diese Methode wird vom Client aufgerufen, wenn er eine Partie spielen
will. Gibt es schon eine Partie des Namens name, die auf einen Gegner
wartet, so wird diese zurückgeliefert, ansonsten instanziiert der
Partie-Manager ein neues Spielpartie-Objekt und liefert dieses zurück.
public String auflisten()
Liefert in einem String die Namen aller Spielpartien (getrennt durch
CRLF) zurück, die im Moment auf einen Gegner warten.
-
Partie4gewinntImpl.java
Das Spielpartie-Objekt. Wird vom Partie-Manager instanziiert und enthält
die Spiellogik sowie das Spielfeld in Form eines Arrays.
Die öffentlichen Methoden:
public short init(org.omg.CORBA.IntHolder clientTicket)
Wird von jedem der beiden Spieler zu Beginn aufgerufen. Liefert dem
aufrufenden Client seine Spielernummer (1 oder 2) zurück.
Außerdem erhält jeder Spieler über einen out-Parameter
ein "Ticket", d.h., eine Zufallszahl, mit der er sich in Zukunft bei der
Übermittlung von Spielzügen ausweist.
Das Spiel kann beginnen, sobald init zweimal aufgerufen wurde,
d.h., sobald zwei Spieler vorhanden sind.
public short status(int clientTicket)
Liefert dem Spieler, der sich über sein Ticket ausweisen muß,
Informationen zum Spielverlauf, z.B. ob er an der Reihe ist oder ob das
Spiel schon zu Ende ist.
public short ziehen(int clientTicket, short spalte)
Wirft einen Spielstein in die mit spalte angegebene Spalte des
Spielfelds.
Liefert den Status nach dem Spielzug oder einen Fehlerstatus bei ungültigen
Zügen zurück.
public short[][] holeSpielfeld()
Liefert das aktuelle Spielfeld zurück.
-
MeisterImpl.java
Das Computerspieler-Objekt.
Die öffentlichen Methoden:
public short besterZug(short spieler, short[][] feld)
Untersucht das Spielfeld feld und liefert den besten Zug für
den Spieler zurück, dessen Nummer in spieler übergegeben
wird.
public void spielstaerke(int maxZeitMillis)
Legt die Spielstärke des Computerspielers fest. Als Eingabe wird
die Zeit erwartet, die der Computerspieler zum Überlegen brauchen
darf (genauer: Der Computerspieler überlegt insgesamt genau maxZeitMillis
* 7/3).
-
Client.java
Das Clientprogramm.
Die main-Methode sucht zunächst einen Partie-Manager und
zeigt dann folgendes Menü:
1) Partie spielen
2) Computergegner starten (Java)
4) Computerbedenkzeit einstellen
5) Partien auflisten
7) Ende
(Fehlende Nummern werden in den folgenden Aufgaben ergänzt.)
Beim Anwählen der Menüpunkte passiert folgendes:
1) und 2):
Die private Methode private static void spielen(String partieName,
int spielerTyp) wird aufgerufen.
Diese Methode erwartet als Argumente den Namen der Partie, die gespielt
werden soll, sowie einen Spielertyp, der besagt, ob der Client während
des Spiels die Spielzüge der Tastatur entnehmen oder ob er in jeder
Runde den Computerspieler nach dem besten Zug fragen soll.
Beim Aufruf von spielen passiert folgendes:
1. Bei Bedarf (Spielertyp > 1) sucht der Client einen Computerspieler
und stellt mittels dessen spielstaerke-Methode die unter Menüpunkt
4) gewählte Spielstärke ein.
2. Der Client ruft die Methode spielen des Partie-Managers auf
und erhält von diesem ein Spielpartie-Objekt.
3. Der Client ruft die init-Methode der Spielpartie auf und
erhält so Spielernummer und Ticket.
4. Innerhalb einer Schleife wird der Status der Spielpartie abgefragt
und -wenn der Client an der Reihe ist- ein Spielzug ausgeführt.
4):
In einer Variable wird die gewählte Spielstärke gespeichert.
In der spielen-Methode wird diese Variable -beim Spiel mittels Computerspieler-
ausgewertet.
5):
Die auflisten-Methode des Partie-Managers wird aufgerufen und
der zurückgelieferte String ausgegeben.
-
Server.java
Wir wissen, daß jedes Objekt ins Implementation Repository eingetragen
werden muß und daß für die Aktivierung der Objekte gesorgt
werden muß.
Da wir der Einfachheit halber Partie-Manager und Computerspieler auf
einem Rechner laufen lassen, erledigen wir dies für beide Objekte
in einem einzigen Serverprogramm.
Dieses Programm initialisiert den ORB und den BOA, instanziiert die
beiden Objekte und aktiviert sie mit Hilfe des BOAs und wartet dann auf
eingehende Anfragen.
Die Java-Klassen sind zusammengefaßt in den Packages ClientAufg1
und ServerAufg1. Ein drittes Package VierGewinnt wird beim
Compilieren der IDL-Datei generiert.
Die Package-Dokumentationen zu allen drei Packages finden Sie HIER.
Ihre Aufgabe:
-
IDL-Datei vervollständigen
Ergänzen Sie die Datei VierGewinnt.idl um die Interfaces
der Objekte, die per CORBA im Netz bereitgestellt werden sollen.
Hinweis: Bis auf einen einzigen sind alle Parameter vom Typ in.
Lediglich die init-Methode des Spielpartie-Objekts hat einen out-Parameter.
Compilieren sie anschließend die IDL-Datei mit dem Kommando idl2java
VierGewinnt.idl -no_tie.
-
Server vervollständigen
Die Datei Server.java ist bisher lediglich ein Gerüst. Machen
Sie daraus ein funktionsfähiges Programm, das die oben erläuterten
Aufgaben erledigt.
-
Client vervollständigen
In Client.java müssen die Methoden
private static PartieManager holeManager() und
private static Meister holeMeister(int typ)
vervollständigt werden.
Diese Methoden dienen dazu, dem Client den vom Serverprogramm per CORBA
bereitgestellten Partie-Manager bzw. Computerspieler zu finden.
Aufgerufen wird holeManager zu Beginn der main-Methode,
holeMeister
am Anfang der spielen-Methode des Clients.
-
Anwendung starten
Bringen Sie die Anwendung zum Laufen!
Hinweise:
-
Sie müssen nur die drei eben erwähnten Dateien verändern,
in den übrigen Dateien gibt es nichts zu tun.
-
In den Dateien sind die Stellen, an denen sich Ihre Aufgaben befinden,
folgendermaßen markiert:
// HIER BEGINNT IHRE AUFGABE
// HIER ENDET IHRE AUFGABE
-
Die Zip-Datei mit den benötigten Dateien finden Sie HIER.
-
Bearbeiten Sie die Aufgabe auf einem SOLARIS-Rechner, z.B. remote auf
murphy, carijo, linus, tim, etc.
-
Zuerst müssen noch einige Umgebungsvariablen gesetzt werden.
Führen Sie dazu (nach dem Entpacken der Zip-Datei) das Kommando
source
vbroker.csh im Verzeichnis Aufgabe1 aus. Vorher sollten sie
die Datei allerdings anpassen: Suchen Sie sich einen Port zwischen 14001
und 14999 aus und ändern Sie dementsprechend die Zeile
setenv OSAGENT_PORT 15000
ab. Damit verhindern Sie, daß Ihre Clients die Objekte Ihrer
Praktikumskollegen ansprechen.
Achten Sie darauf, daß die Umgebungsvariablen auch wirklich in
jedem Bildschirmfenster gesetzt sind, welches Sie bei der Aufgabe benutzen.
-
Im Bildschirmfenster, in dem ein Computerspieler laufen soll (also dort,
wo sie das Serverprogramm starten), muß eine weitere Umgebungsvariable
gesetzt werden. Geben Sie dort vorher das Kommando
setenv THREADS_FLAG native
ein. Andernfalls mißachtet der Computerspieler das ihm zum Nachdenken
gesetzte Zeitlimit.
-
Bevor Sie ihre class-Dateien ausführen können, müssen Sie
auf dem Server-Rechner das Kommando osagent (als Hintergrundprozeß)
starten. Dieses unterstützt den BOA.
-
Ihre class-Dateien starten Sie mit dem Kommando vbj.
-
Beachten Sie beim Compilieren und Ausführen der Dateien, daß
die Klassen in Packages organisiert sind.
Compilieren Sie also vom Verzeichnis Aufgabe1 aus, z.B. mit
dem Kommando javac ServerAufg1/*.java.
Ebenso starten Sie die Programme vom Verzeichnis Aufgabe1 aus,
z.B. mit dem Kommando vbj ClientAufg1.Client.
-
Achten Sie nach dem Beenden der Programme und beim Ausloggen darauf, daß
Sie all Ihre Prozesse beendet haben (auch die Hintergrundprozesse).
-
Denken Sie auch an die anderen User, die auf Ihrem Rechner eingeloggt sind
und verursachen Sie nicht durch langes Spielen gegen den Computerspieler
eine unnötig hohe Prozessorlast!
Diese[r Teil (also Teil zu Blatt 2) der] HTML-Seite an sich sowie die Zusammenstellung dieser Programme
und Dokumentationen sind urheberrechtlich geschützt.
© 1999 Michael Dom und Wolfgang Westje
Alle Rechte vorbehalten.
Betreuung der Aufgabe : Stefan Munz
Abgabe der Lösungen per E-Mail an Stefan Munz
Unter dieser Mailadresse können Sie auch jederzeit Fragen zum Thema
stellen.
Als Abgabe werden funktionierende Versionen der drei zu vervollständigenden
Dateien erwartet.
Aufgabenblatt 3 - CORBA mit Java 2: CORBAservices: Naming Service
Übersicht:
Was sind CORBAservices?
CORBAservices sind eine Sammlung von Diensten auf Systemebene, die
CORBA-Objekte um mehrere nützliche Eigenschaften ergänzen bzw.
den Umgang mit Gruppen von Objekten erleichtern. Während das einfache
Objekt nur vom Applikationsprogrammierer gegebene Eigenschaften aufweist,
kann man mit Hilfe der CORBAservices allgemeine Objekteigenschaften (objekt-
und implementierungsunabhängig) hinzufügen.
Die CORBAservices sind eine Abstraktionsebene höher als der CORBA
Object Bus anzusiedeln, sie bieten einfache Schnittstellen, um mit CORBA-Objekten
umgehen zu können. Sie geben so dem Applikations- bzw. Komponentenprogrammierer
Werkzeuge in die Hand, die er sonst zum Teil selbst erstellen müsste,
und beschleunigen so die Programmentwicklung.
Folgende Grafik zeigt eine Einordnung der Services in die Hierarchie
der Komponentenprogrammierung unter CORBA:

Business Objekte sind in diesem Zusammenhang Top-level-Objekte, die sich
idealerweise wie Objekte in der realen Welt verhalten und vollkommen von
technischen Details abstrahiert sind.
Die CORBAservices sind reine CORBA-Objekte und ihre Schnittstellen vollständig
in IDL geschrieben. Die Spezifikation ist in CORBAservices:
Common Object Services Specification festgelegt.
Die CORBA-Implementierungen der verschiedenen Anbieter enthalten nicht
immer alle hier vorgestellten Services.
Momentan sind folgende 15 CORBAservices spezifiziert:
-
Naming Service:
erlaubt es, Objekte ähnlich wie Dateien in einem Dateisystem mit
Namen zu versehen und sie anhand dieser Namen wiederzufinden.
-
Event Service:
stellt einen Nachrichtenkanal zur Verfügung, an den sich Nachrichtenkonsumenten
und -lieferanten dynamisch anschließen und Nachrichten empfangen
bzw. verschicken können.
-
Life Cycle
Service:
bietet die Möglichkeit, Gruppen von Objekten zu erstellen, zu
löschen, zu kopieren und zu bewegen.
-
Persistent
Object Service:
gestattet, Objekte in einem persistenten Zustand zu halten.
-
Transaction
Service:
steuert Transaktionen zwischen Objekten.
-
Concurrency
Control Service:
koordiniert den gleichzeitigen Zugriff mehrerer Objekte auf gemeinsame
Ressourcen.
-
Relationship
Service:
macht es möglich, Objekten dynamisch Rollen zuzuweisen und Beziehungen
zwischen Objekten zu definieren, um Graphen von Objekten zu erstellen,
die beliebig durchlaufen werden können.
-
Externalization
Service:
bietet einen allgemeinen Weg an, Daten aus einem bzw in ein Objekt
zu ex- oder importieren.
-
Query Service:
erlaubt Objekten Anfragen an eine Sammlung von Objekten zu stellen;
basiert auf SQL bzw. OQL.
-
Licensing Service:
überwacht, ob Objekte konform der Lizenz des Herstellers benutzt
werden.
-
Property Service:
kann dynamisch Objekte mit Eigenschaften ("named values") assoziieren
und diese manipulieren.
-
Time Service:
stellt Methoden zur zeitlich Synchronisation und Zeitmessung zur Verfügung,
sowie die Möglichkeit mit zeitgesteuerten Ereignissen zu arbeiten.
-
Security Service:
schafft eine umfassende Sicherheitsumgebung die u.a. Identifizierung
und Authentifizierung, Authorisierung und Zugriffskontrolle sowie sichere
Kommunikation beinhaltet.
-
Object Trader
Service:
stellt eine Art "Gelbe Seiten" für Objekte und ihre Dienste dar.
Er erlaubt es Objekten, ihre Dienste bekannt zu machen und anderen Objekten
dynamisch nach diesen Diensten zu suchen.
-
Object Collection
Service:
macht es möglich, Objekte in allgemeiner Weise in Sammlungen wie
z.B. Listen, Mengen oder Bäumen einzugliedern und diese zu manipulieren.
Der Großteil dieser Dienste vereinfachen den Umgang mit Gruppen von
Objekten, nämlich Object Collection Service, Trader Service, Query
Service, Relationship Service, Life Cycle Service, Event Service, Naming
Service, Property Service.
Der Rest fügt zu Objekten Funktionalität hinzu, die im professionellen
Gebrauch in einer verteilten Umgebung benötigt werden. Hierzu zählen
Security Service, Time Service, Concurrency Control Service, Transaction
Service, Externalization Service, Licensing Service, Persistent Object
Service.
Der Hauptnachteil der CORBAservices besteht meiner Meinung darin, daß
sie, da sie vollkommen auf der CORB Architektur beruhen, auf eine sehr
effiziente Implementierung des ORBs angewiesen sind, um eine ausreichende
Skalierbarkeit zu gewährleisten.
Für einen Überblick über die CORBAservices ist das Buch
Instant
CORBA, (Wiley 1997) von Orfali / Harkey / Edwards sehr gut geeignet.
Was ist der Naming Service?
Der Naming Service dient dazu, Namen an Objekte zu
binden, um Objekte
sich gegenseitig anhand ihres Namens finden zu lassen. Eine
Namensbindung
wird immer relativ zu einem
Namenskontext definiert, dem Äquivalent
zum Verzeichnis im Dateisystem, indem sie eindeutig sein muß. Ein
Namenskontext kann auch an einen Namen gebunden werden, so ist es möglich
eine Namenshierarchie aufzubauen:
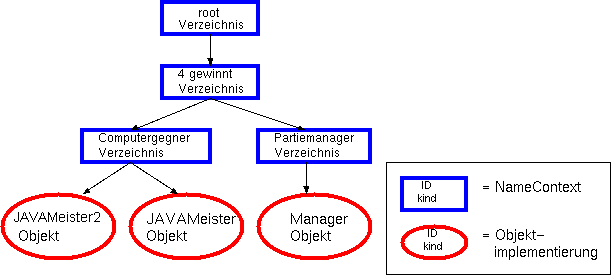
Man kann dasselbe Objekt mit mehreren Namen zu versehen, ähnlich
wie mit "links" unter dem Unix-Dateisystem. Im Gegensatz zu Dateisystemen
gibt es beim Naming Service aber keinen Wurzelkontext auf dem alle Namensbindungen
beruhen und somit auch keine absoluten Namensbindungen.
Um den Typ eines Objektes nicht wie bei Dateien syntaktisch in den Namen
einzubauen zu müssen(".txt"), besteht ein Name beim Naming
Service aus einer oder mehreren NameComponent-Strukturen, die sich
aus einer "ID" (dem "Namen") und dem "kind"-Attribut (dem "Typ") zusammensetzen.
Beide Felder sind Strings und beliebig wählbar.
Beispiele:
(folgende Notation der Namen mit Klammern
und Anführungszeichen ist willkürlich; die Schreibweise als JAVA-code
wird später beschrieben)
Name des Manager-Objekts im [{"4 gewinnt","Verzeichnis"}]
Namenskontext:
[{"Partiemanager", "Verzeichnis"},{"Manager","Objekt"}]
Name des JAVAMeister-Objekts im [{"Computergegner","Verzeichnis"}]
Namenskontext:
[{"JAVAMeister","Objekt"}]
Das Ziel beim Entwurf des Naming Service war, ihn einfach und allgemein
zu halten und nur so viel Funktionen zu integrieren wie nötig sind,
um einen Namensbaum/-hierarchie entstehen zu lassen.
Dadurch kann man viele bestehende Namensdienste und Dateisysteme transparent
in den Naming Service kapseln.
Wie programmiert man den Naming
Service?
Dieser Abschnitt beschränkt sich auf die Programmierung der Namensbindung
und ihre Auflösung.
Für eine vollständige Referenz kann man die OMG
Naming Service Specification und die Dokumentation zum VisiBroker
Naming- und Event Service hinzuziehen. In der Dokumentation zur JDK1.2
CORBA Implementierung befindet sich eine Einführung in den Naming
Service, sowie ein dokumentiertes Beispiel
, welches sich für diese Aufgabe besser eignet, als das des VisiBroker.
1.
Starten des Naming Service:
tnameserv -ORBInitialPort <Port>
Aufruf des Servers:
lokal:
java ServerAufg2.Server
-ORBInitialPort <Port>
remote:
java ServerAufg2.Server -ORBInitialPort <tnameserv-Port>
-ORBInitialHost <tnameserv-Hostname>
Aufruf des Clients:
lokal:
java ClientAufg2.Client
-ORBInitialPort <Port>
remote:
java ClientAufg2.Client -ORBInitialPort <tnameserv-Port>
-ORBInitialHost <tnameserv-Hostname>
Aufruf des JAVAMeister2:
lokal:
java ServerAufg2.Meister2
-ORBInitialPort <Port>
remote:
java ServerAufg2.Meister2 -ORBInitialPort <tnameserv-Port>
-ORBInitialHost <tnameserv-Hostname>
2. Holen des Grundkontexts (root context)
Zuerst sollte man das Package
org.omg.CosNaming importieren.
Innerhalb des Clients bzw. Servers erhält man eine Referenz auf
den Grundkontext mit der Methode resolve_initial_references("NameService")
der Klasse org.omg.CORBA.ORB.
Diese allgemeine Objektreferenz muß noch auf einen NameContext
eingeengt werden.
3. Definieren eines Namens
Ein Name wird durch ein Array der Klasse
NameComponent dargestellt:
NameComponent[] simpleName={new NameComponent("westje",
"Verzeichnis")};
Er kann dabei entweder als ein einfacher Name (wie oben), der ein Objekt
innerhalb des jetzigen NameContext bezeichnet, definiert werden oder als
ein zusammengesetzter Name der noch einen Pfad beinhaltet, zusammengestellt
werden:
NameComponent[] compoundName={new NameComponent("home","Verzeichnis"),
new NameComponent("westje","Verzeichnis")};
Wenn man sich unterhalb des NameContext
[{home,Verzeichnis}]
befindet und den Namen
compoundName verwendet bekommt man dasselbe
Objekt, wie wenn man sich im NameContext
[{home,Verzeichnis}]
befindet und den Namen
simpleName verwendet.
4. Binden eines NameContext
Sei
ctx der aktuelle
NameContext und
name der
Name des neuen Kontexts. Mit
NamingContext new_ctx = ctx.new_context();
ctx.rebind_context(name,new_ctx);
bindet man den NameContext new_ctx an den NameContext ctx.
5. Binden eines Objekts
Mit
ctx.rebind(name, obj);
bindet man das Objekt obj unter dem Namen name an
den Kontext ctx.
6. Auflösen eines Namens
Um das eine Referenz auf das Objekt obj unter dem Namen name im Kontext
ctx zu erhalten, benötigt man die Methode resolve der Klasse
org.omg.CosNaming.NameContext:
org.omg.CORBA.Object obj = ctx.resolve(name);
Dieses Objekt muß dann noch auf den passenden Typ "eingeengt"
werden.
Was ist die Aufgabe?
Die Aufgabe besteht darin, den Client und den Server des Vier-Gewinnt-Projekts
aus der letzten Aufgabe um den Naming Service zu erweitern.
Die Objekte, die im Server dem ORB zur Verwaltung übergeben
werden, sollen nun zusätzlich unter den Namen, unter denen sie in
der obigen Grafik eingetragen sind, dem Naming
Service bekannt gemacht werden. Zu dem JAVAMeister und dem Partiemanager
aus der letzten Aufgabe kommt nun noch der JAVAMeister2 hinzu.
Anhand der Einbindung des JAVAMeister2 kann man sehr gut die integrierende
Funktion des Naming Service erkennen, der auch zu Objekten auf anderen
Rechnern / Betriebssystemen / ORBs eine einheitliche Schnittstelle bietet.
Im Client sollen in den Methoden holeMeister(int typ)
und holeManager() die jeweiligen Objekte anhand ihres Namens identifiziert
und in das Programm eingebunden werden.
Bei der Methode holeMeister(int typ) soll anhand des Typs
(COMPUTER_JAVA oder COMPUTER_JAVA2) der JAVAMeister
oder der JAVAMeister2 eingebunden werden.
Die Zeilen, in denen Code eingefügt werden soll, sind durch Kommentare
gekennzeichnet.
Hinweise:
-
Der Server muss aktiv sein ! Benutze am Ende
von
Server.java und Meister2.java:
Thread.currentThread().join();
-
Es müssen die Dateien
Client.java , Server.java
, Meister2.java und VierGewinnt.idl erweitert werden.
Es kann die IDL Datei der letzten Aufgabe benutzt werden.
-
Der OSAGENT wird nicht mehr gebraucht.
-
Es muß der IDLTOJAVA Compiler von JAVA 1.2 verwendet werden.
(Die SOLARIS Version ist im Zip-File. Die NT Version kann man bei SUN
downloaden.)
-
Die Programme laufen, wie schon bei der letzten Aufgabe, unter Solaris.
Für diese Aufgabe benötigt man keine besonderen Umgebungsvariablen.
Es wird nicht mehr der VISIBROKER verwendet sondern der ORB von JAVA
1.2 .
-
Achten Sie bitte darauf, daß Sie alle Prozesse beenden bevor sie
die Rechner verlassen, auch die Hintergrundprozesse.
-
Zum Austesten stehen die Utilities Entbindung (entbindet alles unterhalb
des root context) und NamensLister (listet alle Namen unterhalb
des root context auf) zur Verfügung. Man startet sie im Verzeichnis
in dem das Zip-File entpackt wurde mit:
java Util.NamensLister -ORBInitialPort <Port> bzw.
java Util.Entbindung -ORBInitialPort <Port>
-
Die benötigten Rahmenprogramme und Utilities können hier
als zip-file heruntergeladen werden.
Abgabe der Lösungen per E-Mail an Stefan Munz
Unter dieser Mailadresse können Sie auch jederzeit Fragen zum Thema
stellen.
Viel Erfolg!
-------------------------------------------------------------------------------------------
Diese[r Teil (also Text zu Blatt 3) der ] Webseite, die zugehörigen Programme und Abbildungen sowie
ihre Zusammenstellung sind urheberrechtlich geschützt.
(c) 1999 Michael Dom ,Wolfgang Westje - geändert von Torsten Zey
Alle Rechte vorbehalten.
Blatt 4: Servlets
Zweck der beiden unten vorgestellten Aufgaben ist, daß Ihr erste Erfahrungen mit der Programmierung von
Servlets sammelt. In den folgenden Paragraphen findet Ihr das nötige technische Hintergrundwissen für
die Programmierung der Aufgaben.
Eine allgemeine (nicht technische) Einführung über Servlets findet Ihr
hier.
Inhalt:
Was sind Servlets?
Java Servlets sind spezielle Java-Programme, deren Zweck die Erweiterung der Funktionalität eines Servers
ist. Diese Programme laufen serverseitig, auf einer Java Virtual Machine (JVM) auf dem Server. Der
Client (Webbrowser) braucht Java nicht zu unterstützen. Eine populäre Beispielanwendung für
Servlets ist die Anbindung eines Servers an eine Datenbank.
Zur Kommunikation zwischen Servlet und Server wurde eine plattformunabhängige Schnittstelle definiert, die
Java Servlet API. Ein einmal programmiertes Servlet kann also prinzipiell auf jedem Server laufen, der
diese API unterstützt.
Die Java Servlet API besteht aus folgenden packages:
-
javax.servlet: Enthält Klassen für die Implementierung von generischen
(protokollunabhängigen) Servlets.
-
javax.servlet.http: Enthält Klassen für die Implementierung von Servlets, welche
das HTTP-Protokoll benutzen (HttpServlets).
HttpServlets
Kurzeinführung in das HTTP-Protokoll: Das HTTP-Protokoll ist ein einfaches, verbindungsloses
Protokoll. Verbindungslos bedeutet, daß zwischen Client (Webbrowser) und Server keine permanente,
sondern nur eine temporäre Verbindung besteht.
Wenn der Client etwas vom Server will, schickt er eine sogenannte request an den Server. Eine request
enthält einen HTTP-Befehl, die sog. method, welche angibt, was der Server tun soll. Nachdem der
Server den Befehl verarbeitet hat, antwortet er mit einer response.
Die meistbenutzten HTTP-Befehle sind die Kommandos GET und POST. Etwas einfach
formuliert dient das GET Kommando dazu, Daten vom Server zu bekommen, während POST
benutzt wird, um Daten an den Server zu senden.
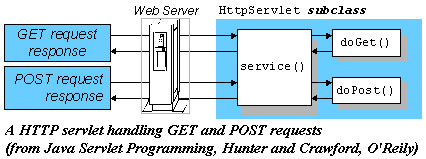
HttpServlets erstellen: Ein HttpServlet erhält man, indem man die Klasse HttpServlet
aus dem package javax.servlet.http erweitert. Ein HttpServlet erhält requests
von einem Webserver (s. Grafik unten) und schickt responses zurück. Die wichtigsten
Methoden dieser Klasse sind:
-
doGet(HttpServletRequest, HttpServletResponse): Verarbeiten von GET requests.
-
doPost(HttpServletRequest, HttpServletResponse): Verarbeiten von POST requests (also
requests, die Daten an das Servlet senden).
-
init(ServletConfig): Wird einmal aufgerufen, wenn das Servlet vom Server geladen wird. Hier kann
man Befehle zur Initialisierung des Servlets plazieren (z.B. Daten aus einer Datenbank holen, die sich
während der Laufzeit nicht ändern).
-
destroy(): Wird einmal aufgerufen, wenn das Servlet vom Server aus dem
Speicher entfernt wird.
Hinweis: In den Aufgaben werdet Ihr nur doGet() bzw. doPost() benötigen.
Wichtig ist zu wissen, daß jedes Servlet-Objekt vom Server nur einmal erzeugt (instanziert)
wird, und danach mehrere Threads des Servers (eins pro request) u.U. gleichzeitig auf dieses Objekt zugreifen.
Falls also member-Variablen (Klassenvariablen) des Servlets verändert werden, ist es notwendig, die
jeweiligen Methoden als synchronized zu deklarieren, um die Konsistenz der Daten zu gewährleisten.
Lokale Variablen, die nur innerhalb von doGet() bzw. doPost() Methoden existieren, sind
davon natürlich nicht betroffen.
Soviel zu Servlets im allgemeinen. Ziel der zweiten Aufgabe auf diesem Blatt ist es, das HttpSession
Objekt kennenzulernen und ein Servlet zu schreiben, welches mit einem (fertigen) Applet kommuniziert.
Die HttpSession
Die HttpSession ist eines der interessantesten Objekte der Servlet API. Mit Hilfe dieses Objekts
ist es möglich, Daten einem unbekannten Benutzer eindeutig zuzuordnen und über mehrere Schritte zu
bearbeiten (Anwendungsbeispiel: Warenkorb). Dazu wird dem Benutzer ein Cookie mit der ID seiner Session
geschickt. Die Daten der HttpSession bleiben jedoch auf dem Server. Wenn der Benutzer sich wieder
meldet, wird über den Wert des Cookies auf die richtige Session zugegriffen.
All das passiert automatisch und transparent. Als Programmierer muß man sich lediglich um das holen bzw.
erzeugen eines Session-Objekts kümmern, sowie um das Schreiben und Lesen der dort gespeicherten Werte.
Dies macht das Benutzen von Sessions sehr einfach und attraktiv. Nützliche Methoden in diesem Zusammenhang
sind die getSession(boolean) Methode der HttpServletRequest und die verschiedenen
Methoden des HttpSession Objekts.
Infos zur Applet <-> Servlet Kommunikation
HttpServlets können nicht nur mit Webbrowsern kommunizieren, sondern auch mit Java Applets,
welche im Webbrowser laufen. Zu diesem Zweck stellt das Applet eine Verbindung zum Servlet her. Es gibt mehrere
Möglichkeiten, diese Verbindung herzustellen:
-
Die einfachste Möglichkeit ist, eine HTTP-Verbindung zu benutzen und Daten als Parameter der GET
bzw. POST requests an das Servlet zu senden. Dies ist ziemlich einfach, weil HTTP-Verbindungen
über das Objekt java.net.URLConnection aufgebaut werden können. Falls Ihr sehen wollt,
wie dies konkret geht, könnt Ihr Euch die Datei HttpMessage.java (bei den Rahmenprogrammen)
ansehen, die auch von unserem MasterMind Applet benutzt wird.
Vorteile dieser Methode sind: die einfache Programmierung (Kommunikation über das HTTP-Protokoll) und
sie funktioniert auch durch Firewalls hindurch. Es ist auch möglich, damit Java-Objekte zu
verschicken, falls diese serializable sind. Nachteil ist, daß die Verbindung jedes
Mal vom Applet hergestellt werden muß, da sie nicht dauerhaft ist. U.a. deshalb ist diese Methode auch nicht
gerade besonders effizient.
-
Eine andere Möglichkeit ist die altbewährte Socket-Verbindung. Nachdem das Applet mit dem
Servlet verbunden ist, ist bidirektionale, dauerhafte und effiziente Kommunikation möglich. Sowohl einfache
Daten, als auch Objekte können verschickt werden. Nachteile: Sie funktioniert nicht durch Firewalls,
ist komplizierter zu programmieren (besonders auf der Servlet-Seite), und man muß sein eigenes
Kommunikationsprotokoll entwerfen.
-
Als dritte Möglichkeit kommt die Benutzung der RMI (Remote Method Invocation) Schnittstelle in
Frage. Vorteile: Elegant, weil keine requests/responses, sondern nur Methodenaufrufe benutzt werden und
objektorientiert. Das Servlet kann Methoden des Applets aufrufen. Funktioniert auch durch Firewalls (aber
noch nicht so gut). Nachteile: Kompliziert zu programmieren, da spezielle Stub und Skeleton
Klassen notwendig sind. Außerdem ist eine RMI-NamingRegistry notwendig, um Referenzen auf die Objekte
zu bekommen. Nicht alle Browser unterstützen defaultmäßig RMI (Stand Ende 98). Außerdem
kann das Servlet dann nur mit Java-Clients interagieren.
Das MasterMind Spiel
In der zweiten Aufgabe werden wir uns mit einem Applet-Servlet Paar befassen, mit dem man MasterMind spielen
kann. Falls Ihr das Spiel nicht kennt, wird es deshalb hier kurz vorgestellt:
Ziel ist es, einen nichtbekannten, fünfstelligen Zahlencode zu finden (der Spielcode). Dazu kann man
beliebig oft einen Spielcode-Kandidaten eingeben. Als Antwort erhält man die Anzahl der Ziffern, die an
richtiger Stelle sind und die Anzahl der Ziffern, die zwar im Spielcode enthalten, aber an falscher Stelle
sind. Hat man 5 Zahlen an richtiger Stelle, so hat man gewonnen.
Bevor Ihr beginnt:
Im Praktikum benutzen wir Apache als Webserver, gekoppelt mit dem WebSphere Applikationsserver von IBM, welcher
die Servlets ausführt. Angebunden ist eine SQL-Datenbank (DB2), in der die Produkte eines fiktiven Pizza-Lieferdienstes
abgelegt sind. Im Rahmen der ersten Aufgabe werdet Ihr einige Produktbeschreibungen aus der Datenbank holen. Um
dies so einfach wie möglich zu gestalten, gibt es ein package namens pizzasvc.db, das
Klassen enthält, welche die Datenbank auf Objekte abbilden. Mehr dazu in der Aufgabenstellung.
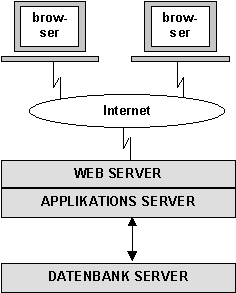
[Das 3-Schichten Modell]
Braucht man extra Klassen? (Ja)
Da die Servlets die Java Servlet API benutzen, braucht Ihr die entsprechenden .jar Dateien. Diese
findet Ihr auf quak.informatik.uni-tuebingen.de unter /usr/opt/home/cspuser/classes.tar.gz.
Die Datei enthält auch das package pizzasvc.db. Ihr solltet ein Verzeichnis in eurem Account
erstellen und das .tar.gz Archiv dort entpacken.
Dann müßt Ihr noch die CLASSPATH Variable auf die .jar Dateien setzen. Im
Beispiel unten befinden sich die Dateien im Verzeichnis myClasses. Der Befehl muß
natürlich in eine Zeile geschrieben werden.
export CLASSPATH=.:/usr/lib/java/lib/classes.zip:
/home/your_id/myClasses/ibmwebas.jar:
/home/your_id/myClasses/jst.jar:
/home/your_id/myClasses/jsdk.jar:
/home/your_id/myClasses/xml4j.jar:
/home/your_id/myClasses/databeans.jar:
/home/your_id/myClasses/
Gibt es Rahmenprogramme? (Ja)
Die Rahmenprogramme für Aufgabe 1 findet Ihr hier und für Aufgabe 2
hier.
Welches JDK kann benutzt werden?
Ihr solltet das IBM JDK 1.1.7B für Linux benutzen. Dies gibt es auf dem Rechner
quak.informatik.uni-tuebingen.de.
Wo muß man die Lösungen ablegen, damit der Server sie findet?
-
Die
.class Dateien Eurer Servlets legt Ihr auf quak, in das Verzeichnis
/usr/opt/IBMWebAS/servlets/aufgaben/user_id, wobei user_id
Eure login ID ist (das Verzeichnis user_id müßt ihr erst noch anlegen).
-
Eure Servlets müssen dem package
aufgaben.user_id angehören, sonst findet
der Server sie nicht!
-
Eure
.html Dateien legt Ihr ebenfalls auf quak in das Verzeichnis
/usr/opt/home/cspuser/public_html/user_id (auch hier müßt ihr das Verzeichnis
user_id erst noch anlegen).
Wie kann man die .html-Dateien/Servlets aufrufen?
-
Damit das ganze funktioniert, müßt Ihr eine HTML-Einstiegsseite in das oben genannte
user_id
Verzeichnis legen und diese mit http://quak.informatik.uni-tuebingen.de/~cspuser/user_id/htmlSeite
aufrufen.
-
Von dieser Einstiegsseite aus und in den folgenden Seiten/Servlets könnt Ihr dann den relativen Pfad
/~cspuser/user_id/Seite benutzen, um .html Seiten aufzurufen.
-
Um Servlets von der Einstiegsseite aufzurufen, müßt Ihr den Pfad
/servlet/aufgaben/user_id/dateiname
(ohne .class) benutzen.
Aufgabe 1
In dieser Aufgabe sollt Ihr ein Servlet erstellen, welches anhand des gesendeten Werts aus dem Formular in der
.html Seite Aufg1.html eine Datenbankabfrage startet und eine .html
Seite mit der Liste der Produkte erzeugt. Erweitert dazu das Rahmenprogramm Aufg1Servlet.java.
Folgende Teilschritte sind notwendig:
-
Die Datei
Aufg1.html so anpassen, daß Euer Servlet aufgerufen wird und diese in das
HTML-Verzeichnis legen, wie oben beschrieben.
-
Nun könnt Ihr mit der Programmierung des Servlets fortfahren. Hier sind folgende Schritte notwendig:
-
Den Wert auslesen. Den Namen erfahrt Ihr in der
.html Seite Aufg1.html.
-
Die Datenbank abfragen: Dazu müßt Ihr die dem Wert entsprechende Produkt-Kategorie aus einer
Liste holen. Dann müßt Ihr diese Produkt-Kategorie an die Produkt-Liste übermitteln und
die Datenbankabfrage starten. Die dazu benötigten Objekte sind schon im Rahmenprogramm definiert.
-
Den Cache abschalten und die Antwort generieren.
-
Nach dem Kompilieren des Servlets die
.class Datei im Verzeichnis für Servlets ablegen
(siehe oben) und die .html Seite aufrufen, um es zu testen.
Tips: Schaut Euch zuerst das Rahmenprogramm an. Dann schaut Euch die Dokumentation der Servlet API an,
insbesondere für die Objekte HttpServlet, HttpServletRequest und
HttpServletResponse. Für die Datenbankabfrage schaut in der Dokumentation des package
pizzasvc.db nach. Links sind unten angegeben.
Aufgabe 2
Zu tun ist folgendes: Es gibt ein Applet, welches eine einfache GUI für ein MasterMind Spiel zur
Verfügung stellt. Das Generieren der Spielcodes und das Überprüfen der Spielcode-Kandidaten
übernimmt ein Servlet. Das Applet kommuniziert mit dem Servlet über ein einfaches
Kommunikationsprotokoll, um dessen Dienste zu benutzen. Die Nachrichten des Protokolls werden vom Applet als
Parameter an die request angehängt, mit der das Servlet aufgerufen wird.
Eure Aufgabe ist es, das Protokoll auf der Seite des Servlets zu implementieren. Im folgenden sind die zwei
Nachrichten des Protokolls beschrieben und was für jede zu tun ist. Eine detaillierte Auflistung der
notwendigen Einzelschritte findet Ihr als Kommentare im Rahmenprogramm mmServlet.java, welches
Ihr auch bearbeiten sollt.
Nachricht 1: Parameter "action" mit Wert "code":
In diesem Fall soll das Servlet eine neue Session erstellen (falls noch keine für diesen
Kommunikationspartner erzeugt wurde). Es soll einen neuen Spielcode erzeugen (mit createCode())
und diesen in die Session schreiben. Außerdem soll es die Anzahl der gemachten Spielzüge (Versuche)
auf 0 setzen und in die Session schreiben.
Nachricht 2: Parameter "action" mit Wert "validate" und Parameter "code" mit Wert: ein
möglicher Code (Code-Kandidat).
In dem Fall soll das Servlet:
-
Den Spielcode aus der Session holen.
-
Den Code-Kandidaten aus dem request-Parameter "code" holen.
-
Die Anzahl der gemachten Versuche aus der Session holen, um eins erhöhen und wieder in die Session
schreiben.
-
Spielcode und Code-Kandidaten vergleichen und das Ergebnis an das Servlet zurückschicken. Das Ergebnis
hat folgendes Format: "<Anzahl_gemachte_Spielzüge>,<Zahlen an richtiger Stelle>,<Zahlen
im Code, aber an falscher Stelle>". Für den Vergleich die mitgelieferte Methode
validateCode(..., ...) benutzen.
Zusätzlich müßt Ihr:
-
Das package Eures Servlets anpassen (aufgaben.userID).
-
Das Applet
mmApplet.java anpassen, so daß Euer Servlet aufgerufen wird (Datei
mmApplet.java, String SERVLET_LOC).
-
Möglicherweise die Seite
mmind.html anpassen, so daß Euer Applet aufgerufen
wird.
-
Die entsprechenden Dateien in Eure Verzeichnisse legen:
mmind.html, mmApplet.class
und HttpMessage.class Dateien in das HTML-Verzeichnis und das Servlet ins Servlet-Verzeichnis.
Tips:
-
Die einfachste Art, den Wert der Parameter aus der request zu lesen (ist aber
deprecated), ist
die Methode request.getParameter(parameter_Name), welche ein Object zurückgibt
(Type-Cast notwendig).
-
Um das Servlet zu testen müßt Ihr das mitgelieferte Applet benutzen. Wichtig: Vorher Cookies
im Browser aktivieren !!
-
---------- WICHTIGE ÄNDERUNG ----------
Zum Debuggen könnt Ihr nach System.err schreiben und dann im Verzeichnis
/var/log in der Datei httpd.error_log nachschauen (auf dem Rechner
quak). Die Strings solltet Ihr noch mit Eurer User-ID markieren, weil alle Servlets dort
reinschreiben, und dann am besten grep benutzen. Einige Exceptions der
WebSphere gehen auch in /opt/IBMWebAS/logs/servlet/servletservice/error_log.
--------------------------------------------
Hinweise
Abgabe: Die .java Dateien der Servlets per email an Stefan Munz schicken. Außerdem solltet Ihr hinzufügen, unter welcher User-ID Ihr die Dateien
abgelegt habt.
Links auf Dokumentation:
Falls Ihr noch mehr Informationen über Servlet-Programmierung benötigt, ist folgendes Dokument sehr
zu empfehlen:
WebSphere Application Server Guide, v. 1.0 (PDF):
- Kapitel 3, Servlet Programmierung
Letzte Aktualisierung [des Aufgabentextes]: Oktober 2000, © Copyright 1999-2000 Elias
Volanakis.
Alle Rechte vorbehalten.
Überarbeitung von
Marc Beyerle.
Aufgabenblatt 5 - OS/390 Teil 1
Hier sind zwei Tutorials zu bearbeiten, die im pdf-Format vorliegen. Daher gibt es an dieser Stelle leider keinen
Aufgabentext.
Die Aufgaben zur OS/390 werden komplett auf der Multiprise an der Uni Leipzig gemacht. Um sich auf der 390 einloggen zu können, benötigen Sie einen Account, den Sie entweder im Raum 022-024 beim Präsenztermin abholen oder per email bei mir anfordern.
Für diese Aufgabe sollen Sie 2 Tutorials nachvollziehen. Die Links für die beiden Tutorials sind:
http://www.ti-leipzig.de/os390/paul/nils/tutor1.pdf
http://www.ti-leipzig.de/os390/paul/nils/tutor2.pdf
Die Abgabe bitte trotz gegenteiliger Behauptung in den Tutorials per Mail an Stefan Munz
Der Inhalt der Abgabe ist in den Tutorials beschrieben.
Zusätzliche Informationen finden Sie unter:
http://www.ti-leipzig.de/os390/paul/index.html
bzw.:http://www.ti-leipzig.de/os390/paul/lehre.html
Folgenden Hinweis erhielten wir:
Da auf der Leipziger 390 Speicherplatzmangel herrscht, löscht bitte alle eure
nicht mehr benötigten DataSets und legt außerdem neue DataSets nur noch
mit kleineren Größen an (10 + 5 KB nicht 2 + 1 MB). Wer dafür Hilfe oder
genauere Infos braucht wende sich bitte an mich.
Bitte meldet euch auch kurz, wenn Ihr nicht mehr benötigte DataSets
gelöscht habt, da ich das sonst tun muss.